
Web scraping as a service
Today we’ll study how to create a web service that is able to scrape the web. Some requirements could be:
- Ability to extract data from DOM and return it,
- Ability to make some conditional browsing,
- Ability to create a job, with params,
- Ability to retrieve result of this time-consuming job.
The stack relies on big classics:
- NodeJS
- Git
- NightmareJS
For the latter : 2 years ago I tried SpookyJS, but I found it quite complicated. Spooky is now not so active, and there is the excellent NightmareJS as a replacement : it allows us to drive a headless browser in a trickless, intuitive way.
The website we will scrape
We will scrape one of the most technology-advanced AI application ever : ask-the-dude : see it here
We can ask the dude any question :
The dude takes time to answer.
The dude always reply
Answer may vary, according to the question
If you forget the trailing “?”, you will have no answer, but in this case, the dude gives you the opportunity to display a random quote.
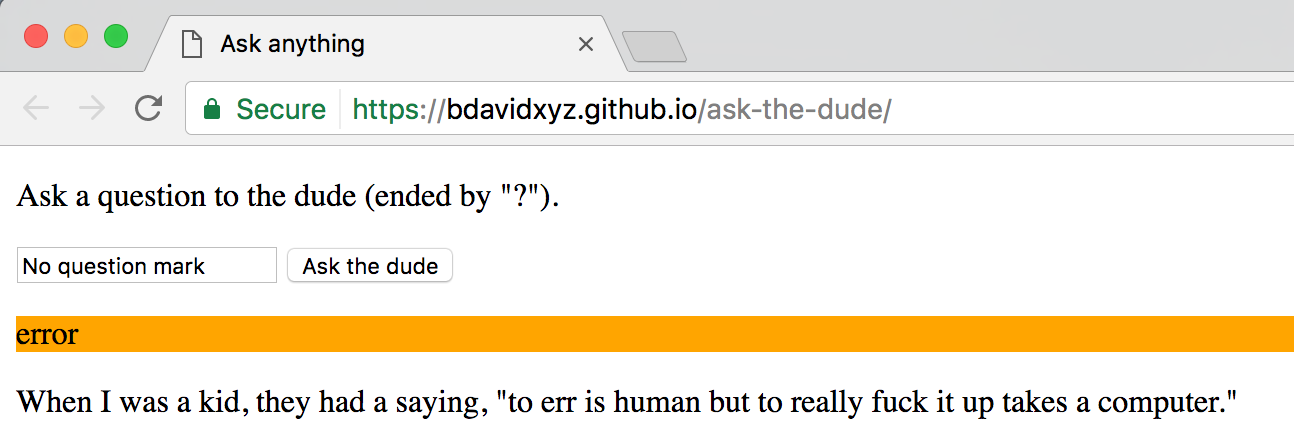
Pretty incredible, isn’t it ?
A bad news
Unfortunately, the ignoble codeur didn’t release any API of “the dude.”
Which means you can’t access to “the dude” programmatically. The only way to get this API is to create a web service that scrapes “the dude”. The API we will create
- POST /ask : Ask a question to the dude. The question is in the body of the request. The API replies “OK” to acknowledge the question, but is unable to answer immediately (remember the dude may take time to think about your question and reply properly).
- GET /get-answer-to?q= : You can use this endpoint a few seconds after the POST : you will get the answer to the question that match with param q.
- GET /all-questions : display all questions already asked, with their associated answers.
Quickstart
$> node --version
v6.9.5
$> git --version
git version 2.7.2
$> git clone git@github.com:bdavidxyz/web-scraping-as-a-service.git
$> cd web-scraping-as-a-service
$> npm install
$> npm start
You can open it at http://localhost:5000/, a welcome message should be printed if everything installed correctly.
Good ! Now our service is ready to be tested.
- Open Chrome
- Open http://code.jquery.com/, — we will use some simple jQuery code to test our service
- Open the console from there (Cmd+Alt+i for Mac users, F12 for Windows users)
- Copy/paste the following code snippets
var a = $.ajax({
type: "POST",
url: "http://localhost:5000/ask",
data: {question:'Do you like butter ?'},
success: function(e){console.log(e);}
});
“OK” should be outputted. Wait a few seconds, then
var a = $.ajax({
type: "GET",
url: "http://localhost:5000/get-answer-for?q=Do you like butter ?",
success: function(e){console.log(e);}
});
You should have the answer to the question. Try now to get an answer to a question you never asked :
var a = $.ajax({
type: "GET",
url: "http://localhost:5000/get-answer-for?q=WTF ?",
success: function(e){console.log(e);}
});
You can also print all questions
var a = $.ajax({
type: "GET",
url: "http://localhost:5000/all-questions",
success: function(e){console.log(e);}
});
Code
Ask a question
The relevant part is here : https://github.com/bdavidxyz/web-scraping-as-a-service/blob/master/index.js#L27-L72
See that NightmareJS is pretty intuitive : you can chain basic instructions very easily. However the famous JS pyramid nightmare (ahem), cannot be completely avoided : once you start to evaluate anything on the page, the result of this evaluation is wrapped in a promise.
You have to be very careful about these 3 things :
- Don’t forget the keyword “return” in front of the nightmare instance inside the promise, or chaining of promises will not occur.
- Don’t forget to re-instantiate NightmareJS on every request.
- Don’t forget to end your nightmare instance once you used it.
Notice that in this example, you can achieve conditional browsing : based on the result of a first evaluation, you can reuse the nightmare instance and scrape the web page again.
Other parts
Great ! Who can do more can do less.
The two other endpoints /get-answer-to?q= and /all-questions don’t use NightmareJS, they are simple, self-describing ExpressJS endpoints.
Concluding thoughts
We have now :
- A completely free way to scrape any website, for free,
- A way to APIfy any website that is not accessible by any other mean than a web browser,
- A way to create some background job,
- A way to do some conditional browsing.
Possible improvements :
- You can deploy the service to a service like Heroku to make your API accessible from anywhere.
- I admit that this doesn’t scale very well, for intensive tasks you may want to use more serious background jobs solutions, and polling an API is also not a very good idea. But that’s enough for today :).